��SMO�㷨���������˺��z�yģ��
���ٙ�Ŀ�������t�W����Փ�� �l�����ڣ�2010-12-22 08:37 ��ȣ�
����ժҪ��ᘌ������˺��z�y�����������S���ߣ�Ҏģ��Ć��}���������������С����㷨����ȼs�p����������˺�������������ͬ�r����ԭ�з���ȣ�����Ӗ���r�g����Folksonomy�������˺��z�y�о��،���·��
�����P�I�~�������˺���������С����㷨���s�p
����
����0�� ����
�����S��Web2.0���g�ܘ����ƏV��������˺�ϵ�yԽ��Խ�ܵ��˂��Ěgӭ�����������ܵ����������SocialSpam���������˺��ĸɔ_��Ŀǰ�z�y�����˺�������;���Ǐ��Ñ��Йz�y������Ͷ���ˣ�ͨ�^��������Ͷ���˵��О飬�_���p�������˺���Ч�����F�Йz�y�����И���ؐ�~˹��[2]���W�j[3]��֧�������C[3]�ȡ�Ȼ����������˺�ϵ�y�Ĕ������O�����F�з���������ֱ�Ӳ��÷���㷨�M�з�z�y���mȻ���в�ͬ�̶ȵ�Ч�������z�y�ٶ������ٔ�����ͨ�^�����OӋ�yӋ�������������S�C��ȡ�ӱ��c�ȷ������s���������@Щ�����mȻ�ܰє�����������һ��СҎģ�ȣ�������һ�������ԣ�������������Gʧ��Ӱ푙z�y���ȡ���ƪ������������С����㷨�s�p��Ҏģ�������˺������������F���z�yģ�͵ă������ڱ��C�z�y���ȵ�ͬ�r���������߷�z�y���ٶȡ�
����
����1. �����˺��z�yģ��
����1.1 Folksonomy�Ñ����������gģ��
������Folksonomy�У�����ϵ�y�w�F���Ñ����˺����YԴ���ߵ��Pϵ�����Ñ�����ʽ�����x��[4]��
�������x��Folksonomy�Ñ����x�����ڽo�����Ñ�uU��Pu��F��u�ļs������Pu:=(Tu��Ru��Iu����u)������Iu:={(t��r)T×R|(u��t��r)Y}��Tu:=1(Iu)��Ru:=2(Iu)����u:={(t1��t2)T×T|(u��t1��t2)��}���@���ʾͶӰ��i��ʾ��iԪ��ͶӰ��
�����������϶��x��֪���Ñ�����������R�^�Ę˺��͌������YԴһ������������ƪ�������˺��z�yģ�͌������@һ���x�������ַ����B�ӵķ�ʽ���˺����YԴ�Y�ϣ����Ñ�ʹ���^�Ę˺��~�R�͌����YԴ�B�ӳ��ַ����ı��������D���ɵõ��µ��Ñ��ı���ʽ���ڴ˻��A�Ͻ��b�ı�������̎�������������M���~�l�з֣������~�䣬Ȼ�������ı����������gģ��[5]���������õ������µ��Ñ�����ģ�ͣ�
����Uk=(Wk1��Wk2��…��Wkg��Wkg+1��Wkg+2��…��Wkh)��
�������У��Ñ����������S���ɘ������~���С�Q����Wki���k���Ñ��ı���ʹ�����~���i�����~�ę��ء�����TF/IDF����Ӌ����ء������е�N��ʾ�Ñ�ģ�Ϳ�����n(i)��ʾӖ������ʹ�Ø˺����~i���Ñ�����
����1.2 SVM����Ҏ��ģ��
����֧�������C(SupportVectorMachines,SVM)��Փ��Vapnik[6][7]��������Á����w���F�yӋ�W����Փ����˼���һ�Nͨ�õČW��������֧�������C��Ӗ���㷨��Ҫ�������һ������Ҏ�����}�����]��ԭʼ���}�Č�ż���}������Lagrange���ӣ��乫ʽ���£�
����(1)
�����ɵ�ԓ���}��������Q�ߺ�����
����(2)
�������С����ϣ�����ÿһ������������һ��Ӗ���c����ˣ�����ķֻ���ƽ��H�H��ه����Щ�����ڲ������Ӗ���c���@ЩӖ���c�ͷQ��֧�������������������ڞ����Ӗ���c�t�Q���֧��������
����
����2. SMO�㷨���������˺��z�yģ��
����2.1 SMO�㷨
����֧�������C�ă����㷨�nj���Ҏģ��ԭʼ���}�ֽ��һϵ��СҎģ���ӆ��}������ij�N�������ԣ���������@Щ�ӆ��}����u���ԭ���}�Ľ��ƽ�ľ��_�ȡ�������С����㷨��SMO��[9]��֧�������C��һ�N���ك����㷨��������С����㷨����Ҫ���E���£�
�����㷨һ
����(1) �xȡ����Ҫ���xȡ����k=0��
����(2) ������ǰ���еĽ��ƽ��xȡ����{1,2,…,l}��һ���Ƀɂ�Ԫ�ؽM�ɵ��Ӽ�{i,j}���鹤����B��
����(3) ����c������B������������}
����
�����ý⣬���˸����еĵ�i���͵�j���������õ��µĿ��еĽ��ƽ⣻
����(4) ���ھ��ȷ����ȝM��ij��ͣ�C�ʄt���t�ý��ƽ⣬ֹͣӋ�㣻��t����k=k+1���D�ڣ�2������
����2.2 �����˺��z�yģ�͵ă����㷨
����ʹ��SMO�㷨�Ĵ�Ҏģ�����˺�Ӗ�����г�ȡ�������Q�����õ�߅��֧�����������㷨�������£�
�����㷨��
�����O��Ӗ���ӱ������ӱ����Ć��}�L�Ȟ�N��
����(1) �������㷨һ��SMO���������ƽ⣻
����(2) ��������ƽ�������������ȡֵ��r��������0�ķ����������е�Ӗ���c���������뼯���С�
����(3) �x��˺���K(ui,uj)�͑��P����C�����첢�������������}��
����
�����õ����
����(4) ͨ�^�x����С��C�����������@��֧��������������Ӌ�㣻
����(5) ��ÛQ�ߺ�����
����
����3. ���
����3.1����OӋ
�������IJ��õĔ���������PKDD2008�ṩ��Spam�z�y��������ԓ�������ɼ��ˇ���֪����������WվSocialbookmarking��BibSonomy�Ĕ������@�ɴ�Wվ���ǻ���Folksonomy��ܵ�ϵ�y���������а���������Ͷ���˺���ͨ�Ñ��Ĕ�������������r���1��ʾ��������ͨ�Ñ���ָ�Wվ���О��������Ñ�������Ͷ����ָ�Wվ���О����Σ���Ե��Ñ����Ñ�������ɾWվ���I�ˆT���^�О��ۙ�����I�����Д��_���ġ�TAS��ָ�Ñ����˺����YԴ���Pϵӛ䛣������S����ָԭʼ�������ı�̎������ֵӋ���õ����Ñ����������ľS����
������1��������r
��
�������Ӳ���h����CPU��P4��3.00GHz��512M�ȴ档�㷨���F�Z�Ԟ�C++���Ñ�ģ�̈́����㷨�е��~�l�з֭h����ʹ��porterstemmer�~����ȡ����ȡ�ı��~�ɡ�SVM�㷨���漰�ĺ˺����x�Ï����������RBF����
����
��������Ҫ�����O�Þ�C=1000��=0.0001��
����3.2���Y��������
�������һ�OӋ��6�M��ͬҎģ�Ĕ�����������֮�g��Ч�����@6�MӖ�����ǰ�ԭӖ����������ؓı�����ȡ���@�á�
������2��ͬҎģ��Ӗ�����������Y������
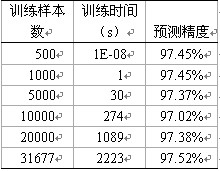
������2�o����6�M�����Č�����r���@6�MӖ���ӱ������քe�Ǐ�500�l��u�U��ԭ������Ҏģ���S��Ӗ����Ҏģ��׃����������ęz�y����һֱ������97%���ϣ��]���^�ӡ��ɴ��f�������ĵ������˺��z�yģ��Ч���Ƿ����ġ����⣬��Ӗ���ӱ������ӵ�5000�l�r���������Ӗ���ٶȳ��F�����@�½��������½��ٶȷdz��졣���@һ�F���C���ˣ������}Ҏģ�U��һ���̶ȕr����ֱ�����Ùz�yģ��̎�����ٶȕ����Fƿ�i��Ӱ푙z�yЧ����
����������һ�M���Ȍ��������˺����ģ�ͷքe��δ̎���^�Ĕ������c����SMO�㷨������Ĕ������M��Ӗ������ʩ����A�y���Y�����3��ʾ��������ĉ��s���_��35.88%��������ț]�Гpʧ������ԭ�е�97.4518%��Ӗ���r�g��ԭ�������38.46%
������3����������ǰ������r����

����
���������ό���֪�����ĵ������˺��z�yģ���mȻ����ȷ�������ֱ�ӌ��������ڴ�Ҏģ�����������ٶ�ƿ�i�����ñ��������SMO�㷨������������������Ч�ĉ��s��������Ҏģ��ͬ�r���pʧ����ȡ�
����
����4. �YՓ
����ᘌ������˺��z�y�����������S���ߡ�Ҏģ��Ӱ푷�z�yģ��Ч���Ć��}�������������SMO�㷨��������������Ч�ļs�p����������˺��������������p�p�z�yģ�͵��\��ؓ�������ķ������H�^����ȵļs�p�������˺�������������߀������ԭ�Д������ķ���ȣ�����Ӗ���r�g���mȻ���ķ�����ԭ���������˃�������������Ҏģ���^����Ҫԭ����ԭ�������S�����ߣ����M�к˾�r���r�^�ߣ�Ч��Ҳ�ܵ�һ��Ӱ푡��Mһ����������ԭ�������M�н��S̎����
����
���������īI
����
����[1] �����,��Ӣ��.�����ھ��е��·���-֧�������C[M].��һ��.����:�ƌW������,2004.
����[2] �����,��Ӣ��.֧�������C-��Փ���㷨�c��չ[M].��һ��.����:�ƌW������,2009.
�����}����SMO�㷨���������˺��z�yģ��
�D�dՈע�����ԣ�http://www.anghan.cn/fblw/dianxin/shengwuyixue/6028.html
���P���}���
�zӰˇ�g�I��AHCI�ڿ����]��Phot...�Pע:106
Nature���¶��W���ӿ�Nature Com...�Pע:152
��С�W�̎�ֵ���˽⣬�@Щ�����W...�Pע:47
2025�ꌑ����WՓ�Ŀ����õ�19��...�Pע:192
�y�L�I��Ƽ������ڿ��x�� �p����...�Pע:64
���r�_Փ�ęz���C������Ҫ�Pע:52
�Ї�ˮ�a�ƌW�ڿ��Ǻ����ڿ����Pע:54
���H������Ҫ�˽�Ć��}����Pע:58
���������ܷ��u�Q���Pע:48
��ŌW����Щ��Ͷ���SCI�ڿ���ֵ...�Pע:66
ͨ�Ź����ИIՓ���x�}�Pע:73
SCIE��ESCI��SSCI��AHCI�ڿ�Ŀ�...�Pע:121
�u�Q�lՓ�ĺ�߀�dz������Pע:68
��ӡ���Y����Ҫ�D�d��Դ�ڿ���...�Pע:51
�����ϢՓ�ķ���
���ܿƌW���gՓ�� �V���ҕՓ�� ��늼��gՓ�� Ӌ��C��Ϣ����Փ�� Ӌ��C�W�jՓ�� Ӌ��C����Փ�� ͨ��Փ�� ��Ϣ��ȫՓ�� ��ӑ���Փ�� ��Ӽ��gՓ�� �����t�W����Փ�� ܛ���_�lՓ��

SCI�ڿ�����
- MEASUREMENT SCIENCE and TECHNOLOGY�п�Ժ�օ^
- MEAT SCIENCE�ڿ������п�Ժ�օ^
- MECCANICA�п�Ժ�ׅ^
- MECHANICAL ENGINEERING�п�Ժ�օ^
- MECHANICAL SYSTEMS AND SIGNAL PROCESSING�ڿ������п�Ժ�օ^
- MECHANICS OF MATERIALS�ڿ������п�Ժ�օ^
- Mechanics of Solids�п�Ժ�օ^
- MECHANICS OF TIME-DEPENDENT MATERIALS�ڿ������п�Ժ�օ^
- MECHANISM AND MACHINE THEORY�п�Ժ�ׅ^
- MECHATRONICS�s־���п�Ժ�ׅ^